

This article shows how to use ROC curves and AUC in R to rigorously evaluate, compare, and threshold-tune classifiers so you can select models that align with real business trade-offs between false positives and false negatives.
Article Outline
Introduction Why evaluating classifiers goes beyond accuracy; how ROC curves illuminate the trade-off between sensitivity and specificity in real-world data science problems.
ROC Curve Fundamentals Definitions of True Positive Rate (TPR/Recall) and False Positive Rate (FPR); how thresholds generate the ROC curve; intuition for the diagonal baseline and the ideal top-left corner.
AUC (Area Under the ROC Curve) and Interpretation What AUC summarizes, how to read values from 0.5 (no skill) to 1.0 (perfect), ties to ranking quality, and when AUC is preferable to accuracy or F1.
R Environment Setup Required packages and roles:
tidyversefor data handling/plots,pROC(and/oryardstick) for ROC/AUC,caretfor consistent modeling APIs, plus model packages (e.g.,glm/statsfor logistic regression,rangerfor random forest,e1071for SVM).Data Preparation Constructing a binary classification dataset with informative and noisy predictors; train/test split; class balance checks; creating a tidy evaluation frame for later plotting.
Training Multiple Classifiers in R Fitting logistic regression (
glm), random forest (rangerviacaret), and SVM (e1071viacaret); extracting calibrated probabilities or decision scores for ROC analysis.Building ROC Curves in R Computing ROC points and AUC with
pROC::roc; plotting multiple ROC curves on one figure; adding confidence intervals and a reference diagonal; tidy approach withyardstick.Comparing Models with AUC and Statistical Tests Interpreting overlapping curves; partial AUCs (high-specificity regions); DeLong test to compare AUCs; business-context discussion of false positives vs. false negatives.
Choosing Operating Thresholds Finding thresholds with Youden’s J statistic; optimizing for cost-sensitive objectives; translating thresholds to expected confusion matrices on the test set.
End-to-End Example in R Complete script: dataset generation → model training → probability predictions → ROC/AUC computation → multi-model ROC plot → threshold selection and confusion matrices.
Common Pitfalls & Best Practices ROC on imbalanced data (contrast with Precision-Recall curves); leakage and nested resampling; averaging across folds; setting seeds for reproducibility; plotting clarity.
Conclusion & Next Steps Recap of ROC/AUC for model selection; guidance on extending to cross-validation summaries, PR curves, calibration curves, and cost-based model selection frameworks.
Introduction
In data science, selecting the right classification model often involves a trade-off between multiple performance metrics. Accuracy alone does not always capture the nuances of model quality, especially in imbalanced datasets. Receiver Operating Characteristic (ROC) curves offer a visual and quantitative method to evaluate and compare classifiers across different thresholds, highlighting sensitivity-specificity trade-offs. This article provides a comprehensive exploration of ROC curves, the Area Under the Curve (AUC), and their use in comparing classifiers in R, complete with an end-to-end example using a simulated dataset.
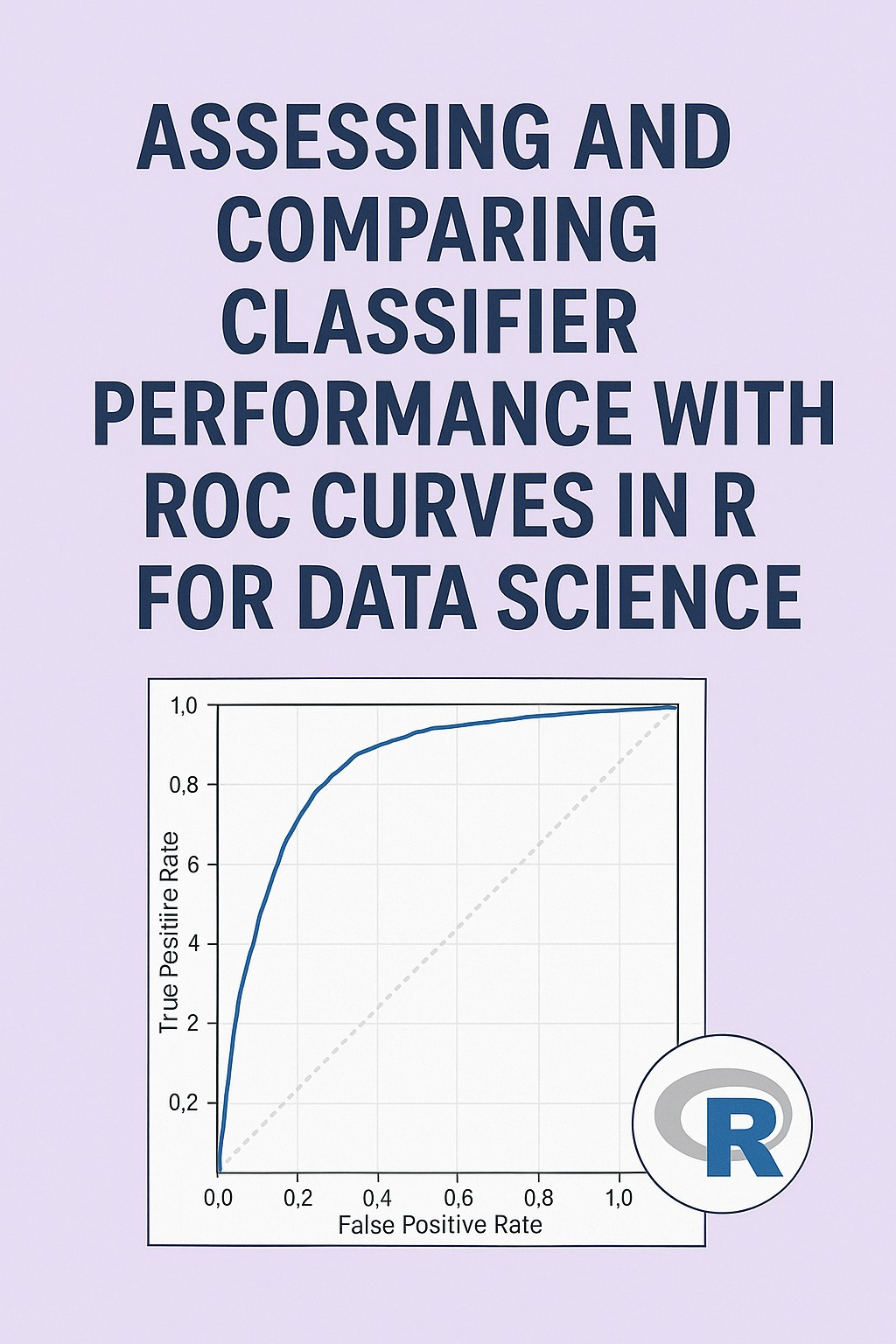
ROC Curve Fundamentals
The ROC curve plots the True Positive Rate (TPR, or sensitivity) against the False Positive Rate (FPR, or 1-specificity) at different classification thresholds. TPR measures the proportion of actual positives correctly identified, while FPR measures the proportion of actual negatives incorrectly classified as positive. By varying the threshold, we trace out the ROC curve, from the lower left corner (all negative predictions) to the upper right corner (all positive predictions). A model with perfect classification ability would reach the top-left corner.
Keep reading with a 7-day free trial
Subscribe to AI, Analytics & Data Science: Towards Analytics Specialist to keep reading this post and get 7 days of free access to the full post archives.